Приветствую! На связи Аксель Фоули.
Может случиться так, что вам срочно понадобилась информация, размещенная на старом сайте.
Вы, преисполненный чувством ностальгии, вбиваете нужный адрес в поисковую строчку, обнаруживаете, что ресурса давно нет. Судорожно ищите в яндексе копию нужного вам текста, но в результате ничего не находите.
Не волнуйтесь — выход есть!
Сервис https://web.archive.org

Это своеобразный мемориал интернета, который содержит дубли умерших веб-страниц. Весь сервис, правда, на английском, но браузерный переводчик на русский язык — спасает...
И сегодня я подробно разберу этот интернет архив сайтов. Кстати, частично данная тема была затронута в статье про покупку домена, где мы проверяли «чистоту» домена, как раз при помощи этого сервиса.
Итак, на вопрос “как восстановить потерянную статью” я даю лаконичный ответ:
Используйте веб.архив.орг
Создателей главного архивариуса глобальной сети следует наградить почетной медалью за вклад в развитие интернета. Что же, разложим все по полочкам.
История создания сервиса
Началась эта история в 1996 году, году предприимчивый программист Брюстер Кайл разработал ресурс под говорящим названием archiveorg.
Проект получился удачный, спустя двадцать лет коллекция сетевого архива включала в себя аж 502 миллиарда копий различных копий веб-страниц.
Кайл поставил перед собой глобальную цель, длиною в столетия: сохранить исторические ценности интернета.
Возможно, что в 1996 году его планы казались наивными, ведь в те годы интернет не представлял собой столь обширного пространства, и не имел такой значимости. Конечно, владелец сайта может поставить запрет на сохранение информации с собственного сайта. И таким образом в базу веб архива такой ресурс не войдет.
Архив периодически пополняется новыми страницами. Для этого существуют специальные боты, которые сохраняют различные сайты в базу. Надеюсь, что и мой блог станет частью истории:)
Уверен, что спустя сотни лет потомки будут конспектировать статьи с этого сайта, собирая информацию по крупицам...
Инструкция по использованию веб — архива
Виртуальная машина времени работает следующим образом:
- Переходите по ссылке https://web.archive.org
- Введите в поисковой строке адрес сайта.

Представим, что этот адрес — volkerball.ru
Это старый сайт, посвященный немецкой рок-группе Rammstein
Ресурса нет в интернете более десяти лет. Ни Яндексу, ни Гуглу не по силам найти его. А вот веб-архив творит чудеса.
Достаточно вбить ссылку в поисковую строчку, и ресурс любезно предоставит вам сохранения.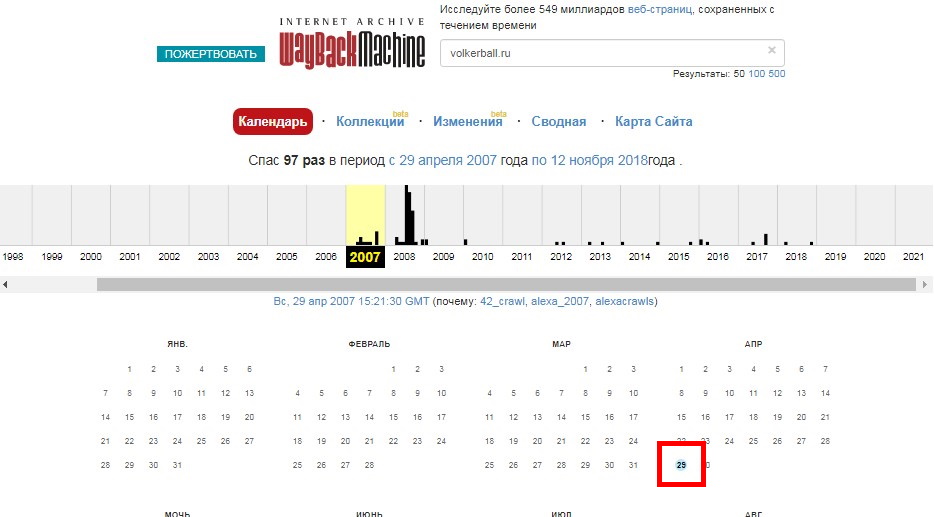 В нашем случае “архивы” затрагивают 2007 год, вы можете выбрать одну из точек выделенных синим цветом.
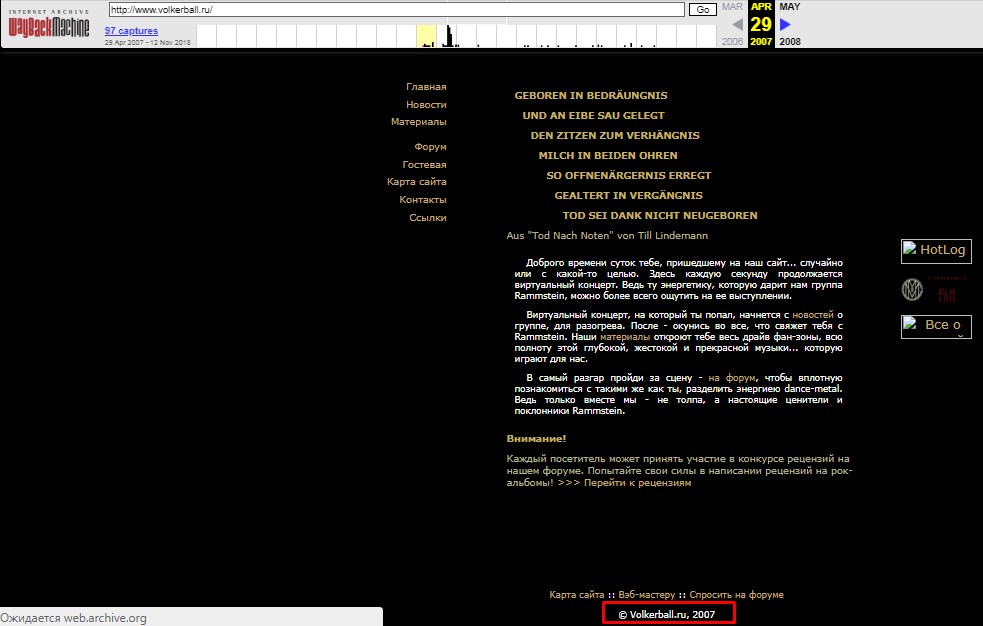
В нашем случае “архивы” затрагивают 2007 год, вы можете выбрать одну из точек выделенных синим цветом.И в результате увидите скриншот из прошлого:
А вот так выглядел форум ресурса в далеком 2007 году:
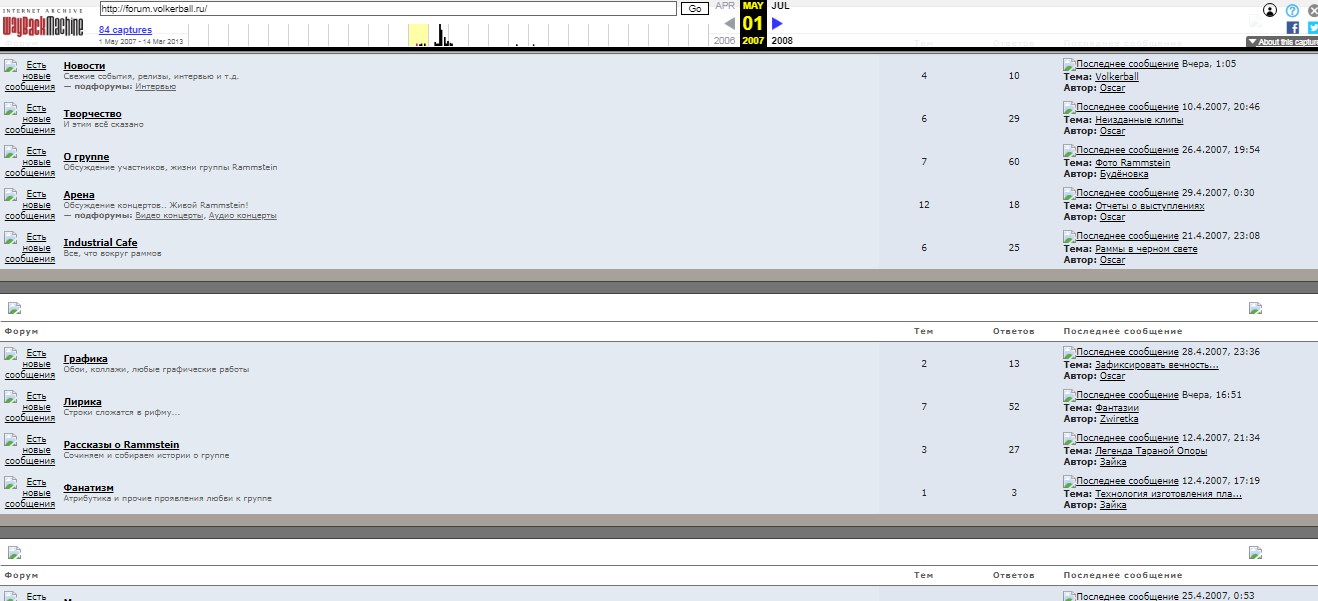
Увы, сейчас и форума тоже не существует. Зато его странички здравствуют на страничках веб-архива.
Итак наш веб-архив — это великолепный удаленный экскурсовод. С его помощью предприимчивый исследователь может проанализировать развитие любой коммерческой компании на протяжении различных периодов времени. Возможно, что спустя несколько сотен лет ваши потомки озадачатся вопросом как найти ваш блог, и веб-архив любезно предоставит эту статью к ознакомлению...
Отдаем сайт в веб — архив
Опять же, все принципиально просто:
- Вы заходите на сайт.
- Кликаете по полю Save Page Now;
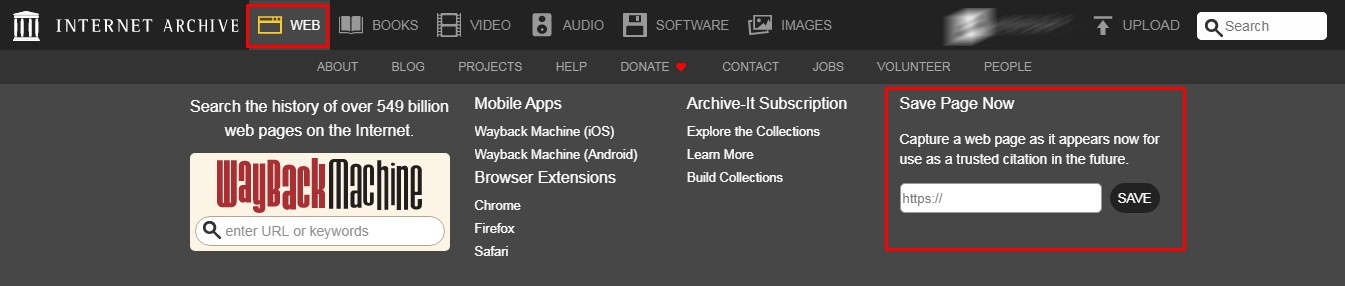
- И сохраняете в нем нужную вам страницу, с сохранением ссылок или без.
Пример: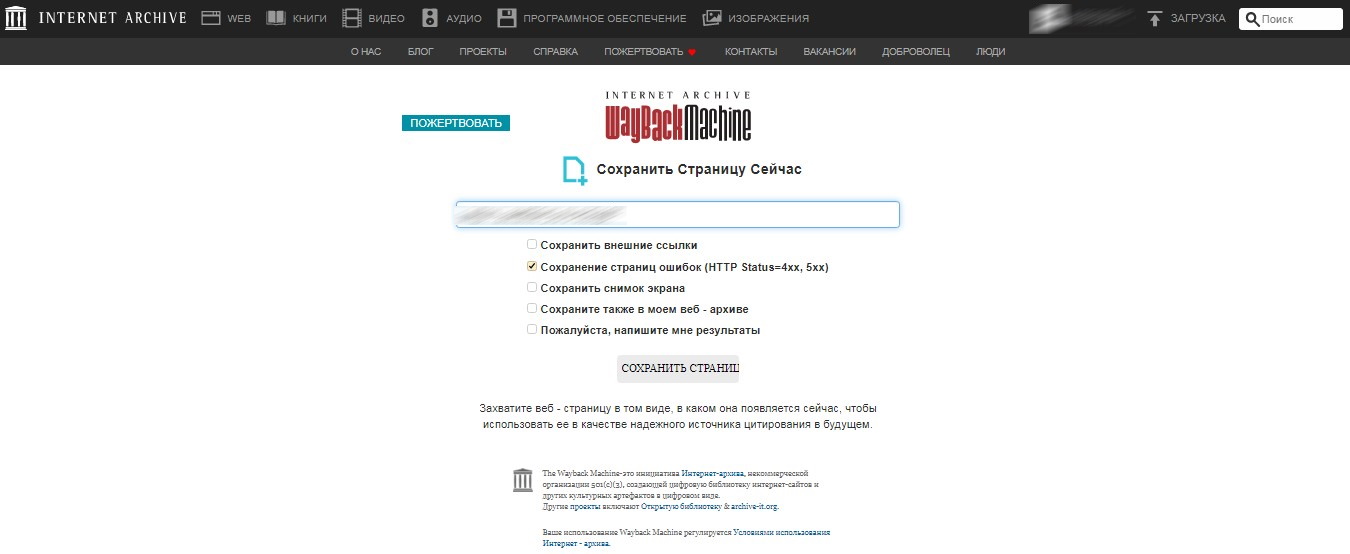
- Пара кликов и страничка сохранена для потомков:
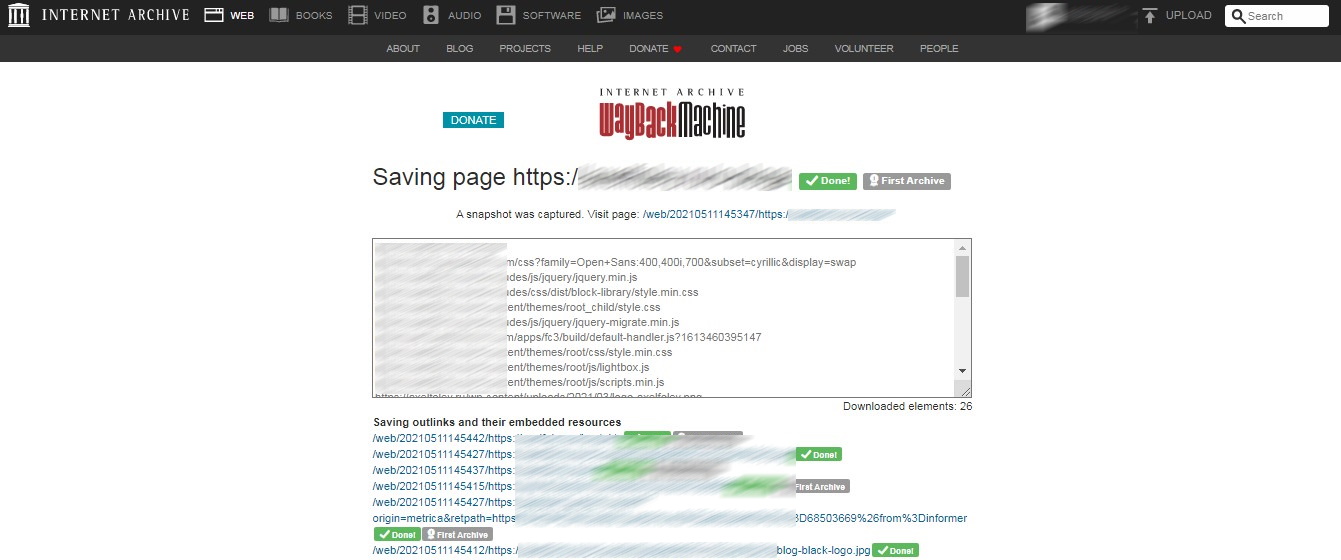
Заключение
Итак, вопрос как посмотреть сайт десятилетней давности закрыт. Конечно, никто не гарантирует, что сохранится или сохранилась именно та страничка, которая вам нужна. Но общее понятие об эволюции того или иного ресурса веб-архив позволяет проследить. Это своеобразная камера сквозь десятилетия, которой, возможно, будут пользоваться наши внуки и правнуки.
Хотите остаться в истории? Сохраните свой сайт прямо сейчас!
С уважением Аксель Фоули.